A large language model is, on its own, a closed book. It knows what was in its training data, frozen at a cutoff date, with no idea what’s in your runbook wiki, your last Jira ticket, or yesterday’s incident review. Retrieval-Augmented Generation (RAG) is the pattern that closes that gap. It’s how you get the model to answer from your documents instead of from memory.
It is also, in 2026, the single most common AI architecture in production — far more common than fine-tuning, and the foundation under most “ask your docs” features shipping inside enterprise tools today.
The two paths
RAG has two paths through the system, and almost every RAG bug is a misunderstanding of which path you’re standing in.
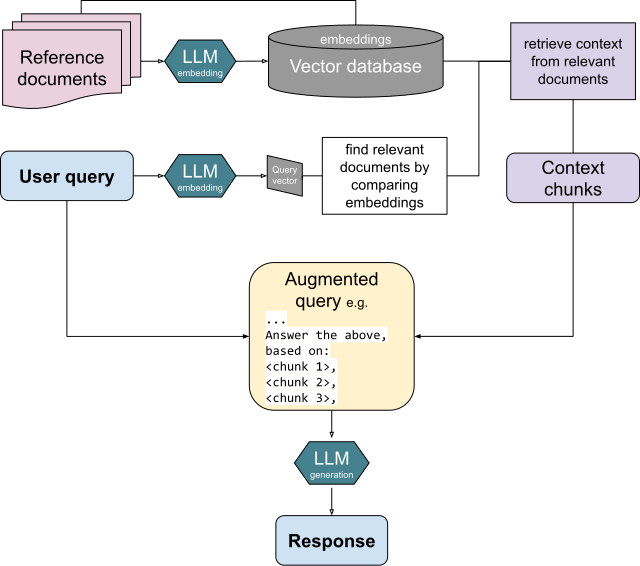
Courtesy: Wikimedia Commons — Retrieval-Augmented Generation process overview
Indexing path (offline). Your source documents — wikis, PDFs, runbooks, ticket history — are split into chunks. Each chunk is run through an embedding model, which produces a vector: a few hundred to a few thousand floating-point numbers that represent the chunk’s meaning. The vectors are stored in a vector index alongside the original text. This path runs on a schedule, or whenever a document changes, and it has nothing to do with the user.
Serving path (online). A user asks a question. The question is run through the same embedding model. The resulting vector is used to search the index for the chunks with the closest vectors — typically by cosine similarity or an approximate nearest-neighbor search. The top-k chunks are stuffed into the prompt as context, along with the question, and the LLM is asked to answer using only the provided context.
The serving path is what users see. The indexing path is where most of your reliability problems will actually live.
Why “retrieval-augmented”
The model isn’t fine-tuned. Its weights don’t change. You’re not teaching it anything new in the long-running sense. You are augmenting each individual generation call with relevant retrieved text — so that the model’s job becomes “answer this question, given these passages” instead of “answer this question from memory.”
That changes three things at once:
- Freshness. Add a document at 9am, ask about it at 9:01am. No retraining.
- Attribution. Because the model answered from a known set of chunks, you can cite which ones. “From your runbook for
auth-svc, section 3…” That’s the part that buys trust. - Scope. A general-purpose model becomes domain-specific without ever leaving its general-purpose weights.
What “good RAG” actually depends on
The architecture is simple. The quality is not. In production, four decisions do most of the work:
Chunking strategy. You can split documents by fixed token count, by heading, by sentence, or by structure-aware parsers that understand the source format. The right choice depends on whether your source is prose, code, tabular, or a mix. Get this wrong and the retriever returns chunks that almost answer the question but are missing the half-sentence that resolves it.
Courtesy: Wikimedia Commons — RAG document styles and chunking patterns
Embedding model choice. Different embedding models cluster meaning differently. A general-purpose model may collapse two distinct domain concepts onto the same vector (“rollback” the deploy action vs “rollback” the database transaction). A domain-tuned or larger model separates them. You only notice in evaluation — never in a demo.
Hybrid retrieval. Pure semantic search misses exact-match cases — error codes, hostnames, ticket IDs. The fix is hybrid retrieval: combine vector similarity with a classical keyword index (BM25 is the typical baseline) and merge the rankings. Almost every serious production RAG system does this.
Reranking. Top-k semantic search is fast but coarse. A second-pass reranker — a smaller cross-encoder model — takes the top 20 candidates and reorders them by direct query-to-chunk relevance. Slower per call, much better signal-to-noise into the prompt.
Where it breaks
The failure modes are not what new RAG implementers expect.
- The retriever returned nothing useful, and the model answered anyway. Without a “I don’t have enough context to answer” path, the model will confidently fabricate. This is the single most common production RAG bug.
- The index is stale. Documents got updated, indexer crashed, nobody noticed. The model is now confidently answering from yesterday’s truth.
- The chunks are right but in the wrong order. LLMs weight the start and end of a long context more than the middle. Reranking matters.
- Per-call cost. Stuffing 20 chunks into every call is fine at 1,000 queries/day and a disaster at 10 million. Caching the embedding for hot queries and capping retrieved-context size both help.
A RAG system that handles those four failure modes — empty-retrieval fallback, freshness monitoring, reranking, and cost-aware context limits — is, in practice, the difference between a demo and something an on-call engineer is willing to depend on.
What RAG is not
- Not fine-tuning. Fine-tuning changes the model’s weights. RAG changes the prompt at call time. They solve different problems and they compose — many production systems do both.
- Not a memory system. RAG retrieves from documents. Agent memory — what was said five turns ago, what the user prefers — is a related but distinct concern with its own patterns.
- Not a free pass on hallucination. RAG reduces hallucination by grounding answers in real text. It does not eliminate it. The model can still misread, over-generalize, or contradict the source.
Where to start
If you’ve never built a RAG system, the smallest useful thing is: take a folder of Markdown files, embed each one with a managed embedding model, store the vectors in pgvector or a single-file SQLite index, and answer a question over them. Forty lines of Python. The result will be mediocre — and that mediocrity is the lesson. Every production knob in this post exists because the naive version is not enough.
References
- Retrieval-augmented generation — Wikipedia — [image courtesy]
- What is RAG? — AWS
- Lewis et al., 2020 — Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (the original paper)
Comments