The word agent is doing a lot of work in 2026. It shows up in product launches, conference titles, and pitch decks — usually with no shared definition of what makes something an agent versus, say, a script with extra steps.
This post is the short version of the definition I actually use, and the classical taxonomy underneath it, framed for cloud and platform engineers who are about to ship — or already shipping — agents in production.
The minimum viable definition
An AI agent is a program that:
- Perceives some part of its environment (logs, metrics, tickets, files, an API).
- Reasons about what to do — typically with a language model in the loop.
- Acts on that environment through a set of tools (function calls, API requests, shell commands).
- Loops — the result of the action becomes new perception, and the cycle continues until a goal is reached or a stopping condition is met.
The loop is the part that matters. A single prompt-and-response is not an agent. Perceive → reason → act → perceive again is. Everything else — memory, planning, multi-agent orchestration — is built on top of that loop.
The classical types
Long before LLMs, AI textbooks (most famously Russell & Norvig) classified intelligent agents into five increasingly capable shapes. The taxonomy still works, and modern agentic systems map onto it cleanly.
Simple reflex agents. Pure stimulus → response. No memory, no model of the world. If alert is firing on host X, run the standard restart playbook. In SRE terms, this is a script triggered by a webhook — agent-shaped, but with no real reasoning.
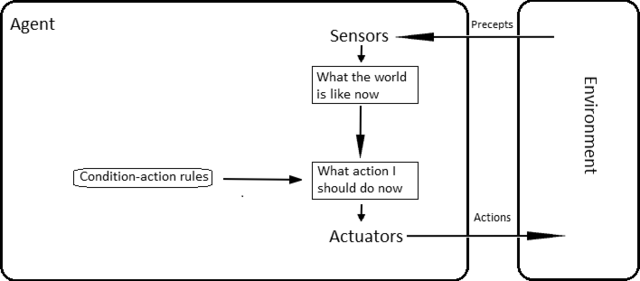
Courtesy: Wikimedia Commons — Simple reflex agent architecture
Model-based reflex agents. The agent maintains internal state — a model of “how the world works” and “what I last saw.” It reacts not only to the current percept but to its accumulated picture of the environment. Last time this alert fired, the upstream service was the real cause; check that first.
Goal-based agents. The agent has an explicit goal, and chooses actions that move it toward that goal — searching or planning across possible action sequences. Goal: restore SLO for checkout-svc. Plan: investigate latency → identify upstream → run remediation → verify. Most modern LLM agents live somewhere in this category.
Utility-based agents. Goals say get there. Utility functions say get there well. The agent weighs trade-offs across multiple objectives — cost, latency, blast radius, on-call disruption — and picks the action with the highest expected utility. This is where production AI tooling earns its keep, because every real SRE decision is a trade-off.
Learning agents. The agent improves over time from feedback. Russell & Norvig’s classical learning agent has four components: a learning element, a performance element, a critic that compares behavior against a standard, and a problem generator that proposes new things to try.
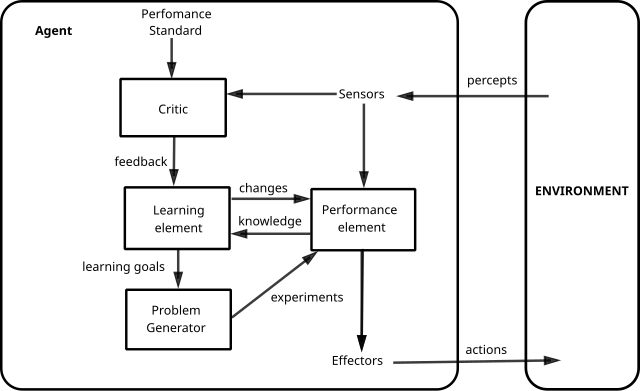
Courtesy: Wikimedia Commons — Learning agent framework (after Russell & Norvig)
In modern terms, the critic is often an eval harness or a human review, the learning element is fine-tuning or prompt iteration, and the problem generator is the part most teams haven’t built yet.
What’s different in the LLM era
The classical taxonomy is intact. What changed is what now sits in the reason box.
- The reasoner used to be hand-coded rules, a planner, or a learned policy. Now it’s frequently a language model.
- The agent’s “tools” used to be domain-specific APIs the agent’s authors hand-wired. Now they’re often discovered at runtime through a protocol — Model Context Protocol is the 2026 default.
- The agent’s “memory” used to be a state machine. Now it’s a mix of conversation history, vector retrieval over past sessions, and structured fact stores.
Same shape, swapped substrate. The reason the taxonomy still earns its keep is that the failure modes still map onto it: a reflex agent fails when the world is more complex than its rules; a goal-based agent fails when its goals are under-specified; a utility-based agent fails when its utility function is wrong; a learning agent fails when its critic is wrong.
Where this matters in production
A practical reframing for platform teams: the unit of autonomy is not “the agent” — it’s the (agent, action, environment) tuple.
The same agent might be fully autonomous on “summarize this incident,” gated behind human approval on “propose a remediation,” and forbidden from ever directly executing “modify production IAM policy.” That’s three different positions on the autonomy ladder, all in one agent, all correct.
That’s a longer argument — I made it in Mental models for applying AI to infrastructure — but the short form is: don’t ask “is my system agentic?” Ask “for this action, in this environment, what’s the right level of human involvement?” Then build the gate that enforces it.
What an agent is not
- Not a chatbot. A chatbot answers. An agent acts. The distinction is whether the LLM’s output can change the state of the world.
- Not a workflow engine. A workflow runs predefined steps. An agent decides which step is next. The line is whether the order of operations is in code or in the model.
- Not magic. An agent is a loop, a set of tools, a memory, and a model. Every one of those is something you have to design and own.
Where to start
The smallest useful agent is a loop with three tools: read, think, act-on-something-cheap. A common starter is “summarize today’s Slack channel”: the agent fetches messages, generates a summary, posts the summary back. Three tools, one loop, one reversible action. Build that first, watch it run, then expand the tool set one at a time.
The patterns that matter at scale — quarantine queues, scope-token exchange, schema firewalls, provenance ledgers — only become real once you have more than one tool and more than one user. But every one of them is built on top of the same perceive-reason-act loop. Get that loop right and the rest is incremental.
Comments