“How reliable is the service?” is the question every reliability-minded team is implicitly answering, all the time. SLIs, SLOs, SLAs, and error budgets are the four numbers that make the answer explicit — and turn arguments about should we ship this into arithmetic.
This post is a primer on each, in the order they need to exist.
A note on framing. I use “SRE” inclusively across this site — DevOps, cloud architecture, platform engineering, and modern reliability practice all share these primitives. SLOs and error budgets aren’t owned by a job title; any team running a production service benefits from naming them.

Courtesy: Google SRE Workbook — Implementing SLOs
SLI — the thing you measure
A Service Level Indicator (SLI) is a quantitative measure of one specific aspect of service behavior. Not a dashboard, not a vibe — a ratio, almost always of the form good events / total events.
Common SLI families:
- Availability —
successful_requests / total_requests - Latency —
requests_under_threshold / total_requests(e.g., requests served in under 200 ms) - Freshness —
pipeline_runs_within_window / total_runs - Correctness —
responses_passing_validation / total_responses
Two rules that save a lot of pain later. Measure where the user is, not at the server — a 200 OK that the client never saw is not a success. And define the denominator carefully — excluding 4xx errors from availability is a defensible choice, but it has to be a choice, not an accident.
SLO — the target you commit to
A Service Level Objective (SLO) is a target for an SLI over a defined window. It is the number the team commits to internally.
99.9% of HTTP requests will return a 2xx or 3xx response in under 300 ms, measured at the edge load balancer, over a rolling 28-day window.
That sentence has all four required parts: the SLI, the target, the measurement point, and the window. Drop any one and the SLO becomes unenforceable.
The famous “nines” are just a shorthand for the target column. Their cost is non-linear:
| SLO | Allowed downtime / 30 days | Allowed downtime / year |
|---|---|---|
| 99% | 7h 12m | 3d 15h |
| 99.5% | 3h 36m | 1d 19h |
| 99.9% | 43m 12s | 8h 45m |
| 99.95% | 21m 36s | 4h 22m |
| 99.99% | 4m 19s | 52m 35s |
| 99.999% | 26s | 5m 15s |
Each additional nine costs roughly 10× in engineering effort. Pick the target that matches what users will notice, not the largest number you can write on a slide.

Courtesy: Datadog — SLO best practices
SLA — the contract with consequences
A Service Level Agreement (SLA) is the externally-facing version of an SLO with a financial or contractual consequence for missing it — service credits, refunds, breach clauses.
The relationship to remember: SLA < SLO. If your SLA promises 99.9%, your internal SLO is 99.95% (or tighter). The buffer between the two is the room you have to be wrong without paying penalties. Teams that set SLO = SLA are running their entire engineering organization on the wrong side of the tripwire.
Not every service has an SLA. Every production service should have an SLO.
Error budget — the currency that falls out
This is where the model gets useful. If your SLO is 99.9% over 28 days, you have implicitly accepted 0.1% unreliability — 40.32 minutes of “bad” in that window. That 0.1% is the error budget.
The budget is currency. You spend it on:
- Risky deploys and schema migrations
- Live experiments and feature flag rollouts
- Infrastructure upgrades
- Anything else that might cause user-visible failure
The point of the budget is what happens when it runs out. The standard policy:
- Budget healthy → ship freely, take on more risk.
- Burn rate elevated → slow down, require more review.
- Budget exhausted → no non-essential releases until it regenerates.
This is the lever that aligns developers and operators without anyone having to argue about whether to ship. The number argues for them. A team that has an SLO but no error-budget policy has half a contract.
A burn rate of 1× means you’re consuming budget at exactly the rate the window allows. 2× means you’ll exhaust the budget in half the window. Most teams alert on multi-window burn rates (e.g., a 14.4× burn over 1 hour and a 6× burn over 6 hours) to catch fast incidents without paging on every blip.
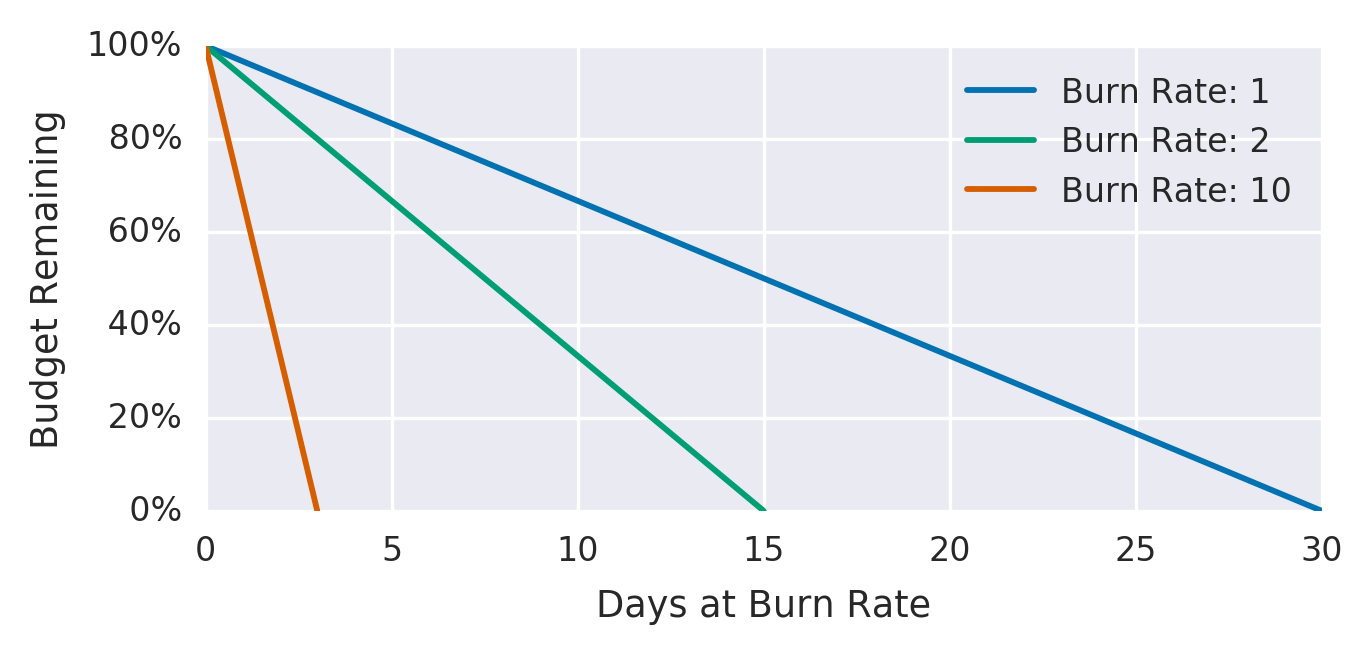
Courtesy: Google SRE Workbook — Alerting on SLOs and Grafana SLO documentation
A worked example
A checkout API team commits to:
- SLI: fraction of
POST /checkoutrequests returning 2xx in under 400 ms, measured at the API gateway. - SLO: 99.9% over a rolling 28 days.
- SLA: 99.5% to enterprise customers, with 10% service credit for any month that misses.
- Error budget policy: at >50% budget burn in 28 days → engineering manager reviews every deploy; at >100% → freeze non-essential releases for one week.
That’s a complete reliability contract on five lines. Most production services don’t have one.
What changes in 2026
The contract doesn’t change when AI agents start showing up in the pipeline — drafting incident reports, triaging alerts, executing remediations. What changes is who can burn the budget.
An agent that auto-restarts a stuck pod is a contributor to your availability SLI, exactly like a human SRE running kubectl rollout restart is. If it gets it wrong twice in a week, it should hit the same budget gate the humans do. The discipline is to keep the SLI measured at the user — did the request succeed? — so the budget remains the honest broker regardless of who or what is driving the change.
This is also why observability for AI-enabled services is becoming a first-class concern: the agent’s behavior is now part of the system you’re measuring, not a tool sitting outside it. And it’s why knowing when not to hand control to an agent is part of the same conversation as setting the SLO — both are decisions about how much risk the budget can absorb.
References
- Implementing SLOs — Google SRE Workbook, Chapter 2
- Alerting on SLOs — Google SRE Workbook — multi-window, multi-burn-rate alerting
- The Art of SLOs — Google’s workshop materials
- Datadog — SLOs explained
- Honeycomb — SLOs the practical way (Charity Majors)
- Grafana — SLOs in Grafana Cloud
- Atlassian — SLA vs SLO vs SLI
- Sloth — open-source SLO generator for Prometheus — practical starting point
- AWS — Operational readiness and SLOs (Well-Architected)
Comments