I wrote a short NAS-vs-SAN comparison several years ago. The table at the bottom of that post — file vs block, ethernet vs fibre, cheap vs expensive — is still correct, and still the right place to start.
What it doesn’t cover is the question most cloud teams are now actually asking: what do I put behind a GPU cluster? That decision is no longer well-modeled by either label on its own.
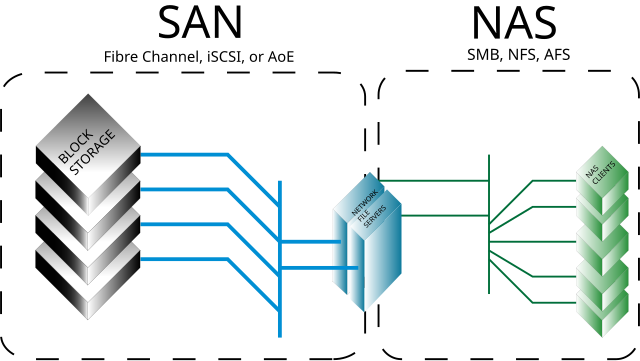
Courtesy: Wikimedia Commons — SAN vs NAS architectural comparison
The classical split, refreshed
To anchor the rest of this post:
- NAS — file-level access over a network filesystem (NFS, SMB). Clients see files. The storage device owns the filesystem. Cheap to add, slower per request, easy to share across many clients.
- SAN — block-level access over a dedicated network (historically Fibre Channel, now also iSCSI and NVMe-over-Fabrics). Clients see raw disks. The client owns the filesystem on top. Faster, more expensive, harder to share.
For a small Postgres cluster, a Hadoop data lake, or a media archive, that’s still the entire decision. For a 64-GPU training run, none of those vocabularies quite fit.
Why GPU workloads broke the frame
Three properties of AI workloads change the storage requirements past anything the original NAS-vs-SAN framing was built for.
1. The throughput floor is high — and parallel. An H100 ingests batches faster than a single 10GbE NIC can deliver. A training run with 64 GPUs reading the same dataset wants tens to hundreds of GB/s of aggregate read throughput, sustained for hours. Neither a 1-controller NAS nor a single Fibre Channel target was built for that shape of demand.
2. The access pattern is bursty and shared. Checkpoints are the obvious case: 32 GPUs synchronously write 200GB of state every N minutes, then read it back if a worker dies. Random small reads dominate during data shuffling, then large sequential writes during checkpointing. No single workload, no single hot path.
3. The filesystem must be sharable across nodes with POSIX-ish semantics.
ML frameworks expect to open(path) and read a file from any worker, often with the same path across hosts. SAN-style raw-block exclusivity (“only one host mounts this LUN at a time”) is the wrong model. NAS-style NFS works, until you push it past one or two controllers and the metadata path becomes the bottleneck.
These three together push the real answer toward a parallel filesystem on top of either substrate — Lustre, GPFS/Spectrum Scale, BeeGFS, WekaFS, or the cloud-native equivalents (FSx for Lustre, GCS with hierarchical namespace, Azure Managed Lustre). None of them are exactly NAS, none are exactly SAN. They borrow from both.
How the calculus actually shifts
The five things that have changed in the decision, in order of how often they bite teams:
Metadata throughput, not just data throughput. Naive NAS dies on millions-of-small-files workloads because the metadata server is single-threaded. Parallel filesystems distribute metadata across multiple servers — that’s the change that lets them scale past plain NFS. If you’re evaluating a “managed NFS” option for AI workloads, the question to ask is not throughput per second; it’s IOPS per second on small-file stat/open calls.
Topology matters more than protocol. GPU clusters run on InfiniBand or 200/400G Ethernet because the GPUs need to talk to each other; the storage fabric usually rides the same network. NVMe-over-Fabrics over RDMA changed what “SAN” means — block storage with NAS-shaped scaling. Calling that decision NAS-vs-SAN is the wrong abstraction.
Object storage came back. S3-compatible object stores (S3 itself, R2, GCS, MinIO on-prem) are now the canonical home for training datasets. Workloads either stream directly from object storage, or use a parallel filesystem as a hot cache in front of it. NAS for “shared files between researchers’ notebooks” still exists, and is still useful. SAN for “primary GPU training storage” mostly doesn’t.
Checkpoint storage is its own workload. Frequent, large, write-heavy, recovery-critical. Some teams now run a separate fast tier (NVMe-backed parallel filesystem, sized for the checkpoint working set) and keep the warm dataset on object storage. The two have different cost, durability, and access-pattern profiles. Treating them as one tier overspends on the dataset side and underprovisions on the checkpoint side.
Inference has a different shape entirely. Inference workloads care about model-weight loading latency at startup, then very little I/O after that. Most production inference fleets pull weights from object storage at pod startup, cache them on local NVMe, and never touch shared storage in the hot path. The NAS vs SAN question doesn’t really apply.
So — what do you put behind the cluster?
A practical default, scaled to the size of the workload:
- A few GPUs, exploratory work — NFS or a managed NAS in front of object storage is fine. Don’t overbuild.
- A single-node-multi-GPU training rig — local NVMe scratch + object storage for cold data. No shared filesystem needed.
- A multi-node training cluster — parallel filesystem (Lustre, FSx, WekaFS, GPFS) sized for checkpoints and the working dataset; object storage as the system of record.
- An inference fleet — object storage for weights, local NVMe cache, nothing shared in the hot path.
The labels that fall out of those choices are a mix of NAS-shaped (POSIX, sharable) and SAN-shaped (block-level performance, RDMA). The original taxonomy still helps you talk to the storage vendor. It doesn’t help you choose.
What hasn’t changed
The unsexy stuff. Snapshots, replication, recovery-time objectives, the meaning of durability in your contract. GPUs make the throughput problem more interesting, but a checkpoint you can’t restore from is still useless. The reliability properties of your storage layer outlast any specific generation of accelerators.
Comments