Five years ago I wrote a short primer on the CAP theorem — three guarantees, pick two, the usual. The theorem hasn’t changed. The systems it gets applied to have.
When your read path runs through a vector index, your write path lands embeddings into that index, and your “answer” is an LLM call that depends on whichever chunks happened to be retrievable in the last 200ms — the CAP trade-off looks the same on paper and feels different in production. Worth a second pass.
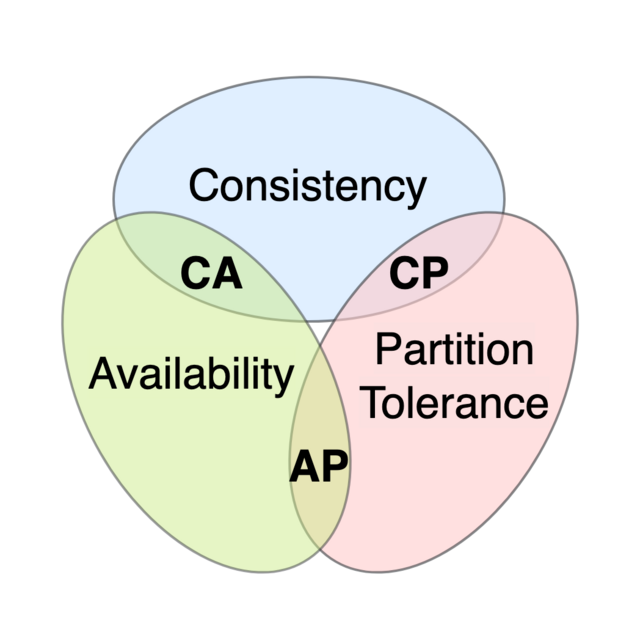
Courtesy: Wikimedia Commons — CAP theorem Euler diagram
A two-line refresher
Eric Brewer’s CAP theorem says that in the presence of a network partition, a distributed datastore can offer at most two of: Consistency (every read sees the most recent write or an error), Availability (every request gets a non-error response), and Partition tolerance (the system keeps working despite dropped or delayed messages between nodes).
In practice, partitions are not optional — networks fail. So the live choice is C vs A under partition: do you stall the read until you can prove it’s current, or do you serve a possibly-stale answer and keep moving?
What’s actually different in AI-native systems
Three things shift when an LLM is in the loop.
1. The unit of “consistency” is fuzzy
Classical CAP assumes a row, a document, a key. An AI-native read isn’t reading the row — it’s retrieving the top-k nearest vectors to a query embedding from an index that may have millions of entries. “Consistent” now has to answer a question the original framing didn’t: consistent with respect to what?
- Consistent index contents (every chunk you indexed is searchable)?
- Consistent ranking (the same query at the same instant returns the same top-k from every replica)?
- Consistent retrieval semantics (the embedding model hasn’t drifted between writer and reader)?
These are three different consistency properties, and most production RAG systems quietly accept eventual consistency on at least two of them. A document indexed at 09:00:00 may show up in some replicas by 09:00:02 and others by 09:00:08. For most retrieval use cases this is fine. For “find me the runbook we just published” during an active incident, it isn’t.
2. Stale answers are worse than missing answers
In a classical AP system, a stale read of a user’s profile is a minor annoyance. In a RAG system, a stale read produces a confident answer grounded in yesterday’s documents, which is much harder to detect downstream than a 503. The model doesn’t know it’s reading from a stale snapshot. The user doesn’t either.
This pushes AI-native systems toward a less-discussed posture: AP with explicit staleness signals. The retrieval layer returns what it has, but tags the response with the freshness of the underlying index — last successful indexing run, lag from source-of-truth, percentage of expected documents present. The application layer then decides whether to answer, qualify, or refuse. CAP doesn’t change. The escalation path on the A side does.
3. Partition tolerance now spans the model boundary
For platform engineers, this is the one that doesn’t show up in textbooks. Your “partition” used to be a network split between two database nodes. Now it can also be:
- The embedding model API is reachable but rate-limited.
- The vector index is reachable but its underlying object store isn’t.
- The LLM provider has a regional outage but your retrieval layer is fine.
- Your retrieval layer is fine and the LLM provider is fine — but the LLM has been updated to a new version overnight, and the embeddings in your index are from the previous one.
That last case is the interesting one. It is a semantic partition with no network failure at all: the writer and the reader speak different languages because the model weights moved out from under them. Classical CAP has no name for this. Production systems still have to handle it.
What this means in practice
A few patterns that fall out of the framing.
Pin embeddings to a model version. Treat the embedding model as part of the data layer’s schema. Re-embedding on a model swap is a migration, not a refresh.
Make freshness a first-class header on retrieval responses. Caller can then choose to fall back to a classical search, qualify the answer (“based on documents indexed before 09:00 today…”), or refuse.
For the answer surface, prefer AP + explicit staleness over CP. Users wait for a few hundred milliseconds; if the only consistent answer takes five seconds, they reload, and now you have two answers in flight. Same logic as classical AP systems — stronger now because LLM responses are slower to begin with.
Reserve CP for the small surfaces where it actually matters. “Has this RFC been approved?” and “Is this credential still valid?” are CP. “What does the team know about service X?” is AP, with a freshness tag. Knowing which is which is the architecture work.
What CAP doesn’t tell you
CAP is about the storage layer. AI-native systems have a whole other axis — per-call cost, prompt-context bounds, rate limits on the model API — that CAP wasn’t designed to reason about. Those constraints often dominate the actual architectural decisions in 2026. CAP is still load-bearing, but it’s no longer sufficient on its own.
For platform engineers, the right framing is: CAP for the datastore, observability for the model boundary, and a freshness contract between them. Get those three right and the rest of the system tends to behave.
Comments