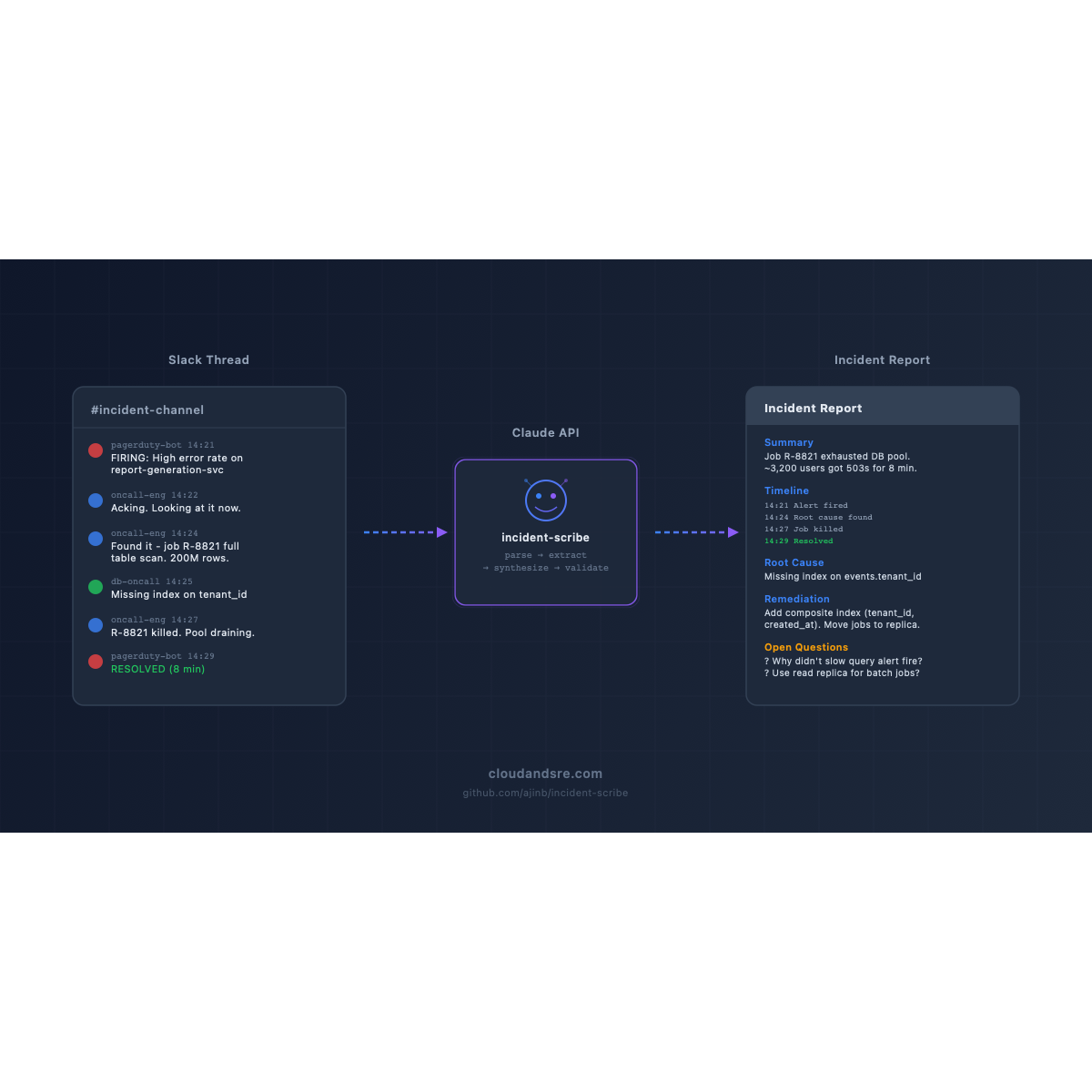
Every incident I’ve ever been on-call for was documented twice.
Once in the Slack thread as it happened — messy, interrupted, full of reactions and false leads. And once, days later, in a postmortem document that nobody wanted to write. By the time the second version existed, the context had faded, the subtle timing of what-happened-when was approximate, and the whole thing was less a blameless learning artifact than a compliance chore.
This post is about a tool I built to close that gap. It’s called incident-scribe. The code is open source at github.com/ajinb/incident-scribe. The design decisions — especially the reliability patterns — are the interesting part, so that’s what I’ll focus on here.
The problem, stated honestly
The dream is: on-call engineer closes the incident, pastes the thread into a tool, gets a ready-to-post-mortem document.
The real problem is subtler than that. A good incident report has to:
- Get the timeline right — timestamps are facts, not impressions
- Be blameless — describe what happened, not who failed
- Separate impact from root cause from remediation
- Flag open questions explicitly, rather than papering over uncertainty
- Not hallucinate — a confidently-wrong incident report is worse than no report
LLMs are strong at three of those (structure, prose, blamelessness) and notoriously weak at two (timestamp fidelity, uncertainty). The engineering work is making the second set work in production.
Architecture
The tool has four stages:
Slack thread → parse → extract → synthesize → validate → reportEach stage is a separate module with a narrow responsibility.
1. Parse
Input is either a Slack export JSON file or a plain-text paste. The parser normalizes both into a single MessageStream — a list of typed records with actor, timestamp, text, reactions, and thread parent.
Parsing is pure Python, no LLM. This matters for two reasons: timestamps stay exact, and a parsing bug doesn’t cost an API call.
2. Extract
This is the first Claude call. The prompt asks Claude to identify discrete events in the thread — an alert firing, an engineer acknowledging, a deploy rolling back — and to tag each event with the message ID it came from.
Key decision: Claude doesn’t generate timestamps. It returns message IDs, and the parser resolves those to timestamps deterministically. The LLM never touches a clock.
The output is validated against a pydantic schema. If validation fails, we retry with a narrower prompt that repeats the specific field that failed. Three retries, then we error out rather than return something wrong.
3. Synthesize
Second Claude call. Given the validated event list and the raw thread, generate prose sections: Summary, Impact, Root Cause, Remediation, Open Questions.
The prompt explicitly instructs Claude to leave fields empty if the thread doesn’t contain enough information, and to list open questions rather than guess. This matters. The failure mode we’re protecting against is confident fabrication.
4. Validate
Final pydantic check. Every field passes through a schema that enforces structure (not content — we’re not trying to judge whether the root cause is “correct”; that’s the engineer’s job).
Reliability patterns, made concrete
The scaffolding around these four stages is where this goes from “cool demo” to “I’d run this in production.” Four patterns, taken from the Azure Well-Architected Framework and adapted for AI in the loop.
Event Sourcing
Every Claude API call — input, output, model version, prompt version, latency, token usage — is appended to an immutable local log. Nothing is overwritten. If a report comes out weird, I can replay exactly what the model was given and what it returned.
This sounds like over-engineering until the first time a stakeholder asks “why did it say X?” and you need to answer that question three weeks later.
Compensating Transaction
incident-scribe supports posting reports directly to downstream systems (Confluence, Notion). If that post fails, the tool doesn’t lose the draft — it writes it to a local .incident-scribe/drafts/ directory and prints the path. The operation is reversible.
The failure case “report generated but downstream post dropped it” is silent and corrosive. The compensating pattern is what makes it loud.
Retry + Throttling
All Claude calls go through a single client wrapper with exponential backoff (tenacity, jittered) and per-tenant rate limiting. Rate limits are enforced client-side; we do not rely on 429s as the primary signal.
Temperature is fixed at 0.2 for extraction, 0.4 for synthesis. Model version is pinned in config. The prompts are version-numbered and logged with every call.
Structured Output
Every LLM response is validated against a pydantic schema before use. This is the single most important reliability pattern for LLM-backed tools. If the model returns malformed JSON, we retry with a narrowed prompt. If it returns syntactically valid JSON that doesn’t match the schema, we retry. If neither works after three attempts, we fail loudly rather than return a broken document.
What I chose not to build (yet)
A tool is as defined by what it excludes as by what it includes. I deliberately left three things out of v1:
- Fine-tuning. The default Claude model is strong enough for this task out of the box. Fine-tuning adds maintenance cost and model-drift risk without measurable quality improvement here.
- An agent loop. This is a pipeline, not an open-ended task. Wrapping it in an agent would add latency and non-determinism for no gain. The right tool for a known workflow is a pipeline.
- A Slack bot interface. Roadmap item, not v1. The CLI is the right first surface because it’s what I actually use.
If I had to name the single biggest mistake I see in AI SRE tooling right now, it’s reaching for agents and fine-tuning when a prompt + schema + retry loop would do the job with 10% of the complexity.
What production felt like
I’ve been running incident-scribe against real post-mortem threads. A few things surprised me:
- Blamelessness is a prompt problem, not a model problem. The default prompt produced reports that occasionally slipped into “Engineer X deployed Y.” A one-sentence system prompt addition (“Describe actions in passive voice or by team, never by individual”) eliminated this entirely.
- Open Questions is the most useful section. More than one stakeholder has told me the open-questions list catches things the human-written versions missed.
- Timestamps were the bug. Early versions asked Claude to generate the timeline. About 10% of the time, timestamps drifted by several minutes — enough to matter for a post-mortem. Moving timestamp resolution out of the LLM entirely was the fix. If you take one thing from this post: keep the LLM away from anything that has a ground-truth answer elsewhere.
Get the code
- Repo: github.com/ajinb/incident-scribe
- Install:
pip install incident-scribe
I’d love feedback — especially from on-call engineers who have opinions about what a “good” incident report looks like. Open an issue, or reach me at cloudandsre.com.
incident-scribe is the second release in the cloudandsre.com open-source toolkit. The first is sre-ai-toolkit. Next up: alert-explainer for Prometheus alert triage.
Comments